Schema proliferation builds slowly and gets expensive fast.

Schema proliferation builds slowly and gets expensive fast.
One schema per event type seems reasonable - until you’re: • Managing 10+ tables • Writing union queries across all of them • Propagating a single field rename everywhere
The Alternative❓ Discriminator-based schema consolidation.
It reduces schema count, simplifies downstream consumption, and makes schema evolution manageable. New variants become additive changes instead of breaking existing consumers.
🔗 Check out the #InfoQ article for a practical look at the pattern and its trade-offs ⇨ https://bit.ly/4uC023n

The Schema Proliferation Problem in Kafka and Flink Pipelines: How to Solve It
Schema proliferation builds slowly and gets expensive fast. One schema per event type feels right until there are ten tables, union queries spanning all of them, and a single field rename touching every schema. Discriminator-based schema consolidation collapses that to two tables, turning multi-table unions into a single query, while new variants are additive and don't break existing consumers.
bit.ly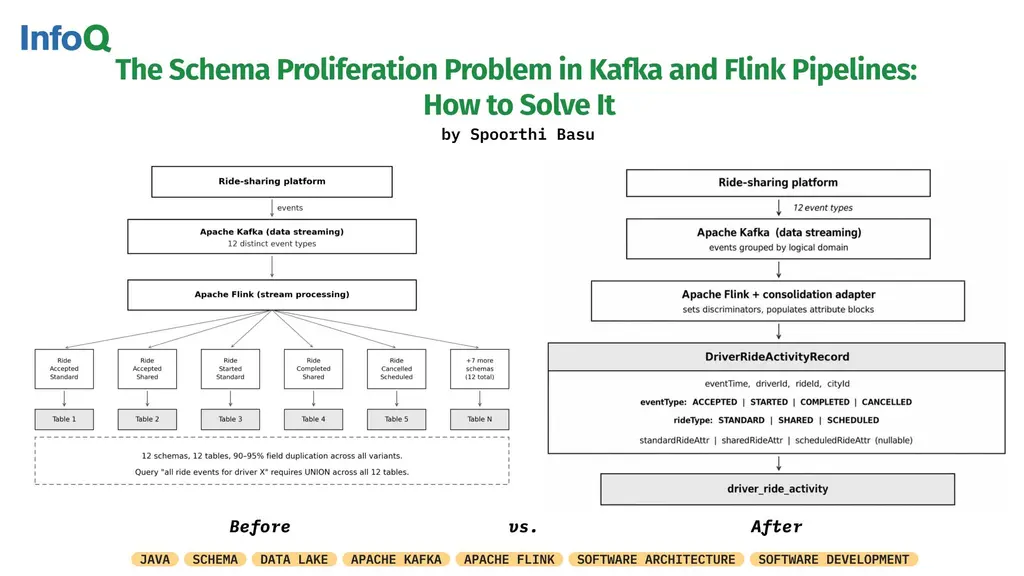
Comments (0)