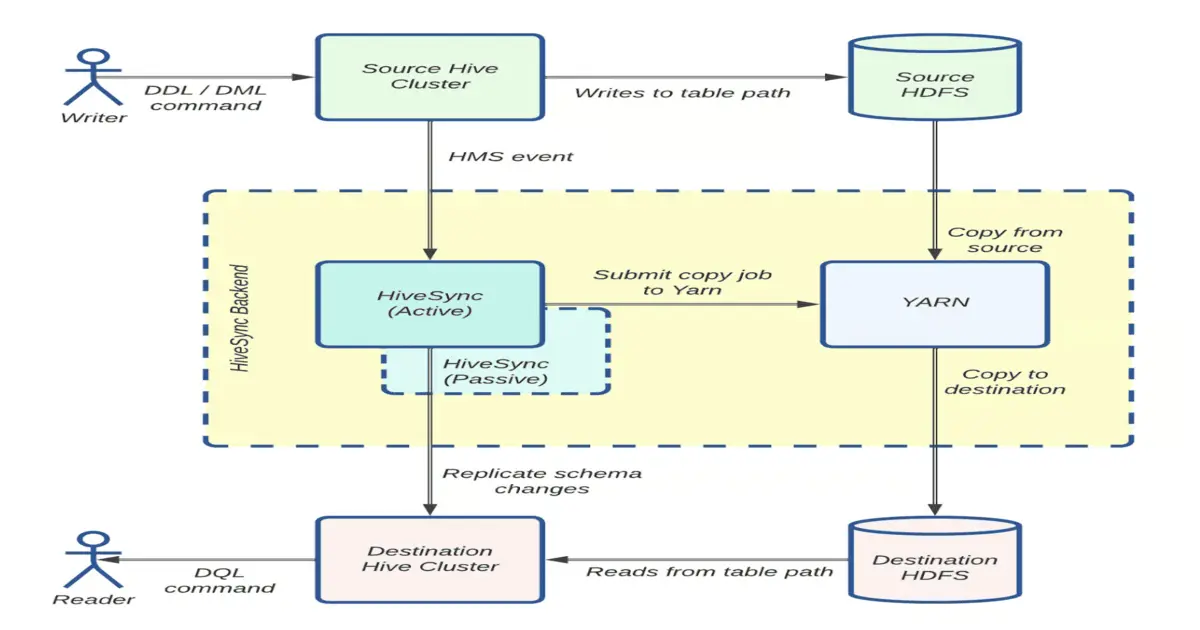
#Uber’s HiveSync team optimized Hadoop Distcp for multi-petabyte replication…

Posted in
資訊系統設計
#Uber’s HiveSync team optimized Hadoop Distcp for multi-petabyte replication across hybrid cloud and on-prem data lakes.
✅ Task parallelization ✅ Uber jobs for small transfers ✅ Improved observability
Result: 5× replication capacity & seamless on-prem-to-cloud migration.
Read more: https://bit.ly/4bwUUFt
#InfoQ #SoftwareArchitecture #DistributedSystems #Observability #DataLake
Hybrid Cloud Data at Uber: How Engineers Solved Extreme-Scale Replication Challenges
Uber’s HiveSync team optimized Hadoop Distcp to handle multi-petabyte replication across hybrid cloud and on-premise data lakes. Enhancements include task parallelization, Uber jobs for small transfers, and improved observability, enabling 5x replication capacity and seamless on-premise-to-cloud migration.
bit.ly
Comments (0)